XOR
XOR 是“异或”运算的简称,是一种基本的位运算。它的运算规则是对两个比特位进行比较,如果两个比特位相同,则结果是0;如果两个比特位不同,则结果是1。


因为≠ 0.5,所以是有信息的。那么即使只有一个子集的值,也能以大致相同的方式利用偏差。甚至0.5000001。
source of info = 如果输入表达式与输出表达式的一致程度不超过 0.5,那么其中一个表达式就是另一个表达式的信息源。
Linear Cryptanalysis
- 明文和密文可见
- 是known plaintext attack
- 足够多的明文和密文对来寻找输入位和输出位之间的线性关系。
- 要求足够好的线性逼近。
- 指 针对块密码发起的一类攻击。
- 通过线性表达式(用 mod-2 比特运算表示的一些变量)来逼近块密码。
- 这些表达式的真(或假)带有一定的偏差,利用这种偏差来发现关键比特。
Substitution Boxes (S-box)
- 确定 S 框的偏差、构建 LAT。
- 用(有偏差的)线性表达式。
- 链接表达式从初始明文到中间密码文本。
- 通过 Matsui的偏差定理。
- 对于最后的子键,确定表达式的成立频率
- 如果匹配偏差,你就发现了密钥!
- 对每个子键重复上述步骤。
以查找表的形式实现的,但不能随着输入量的增加而扩展,因此必须以不同的方式计算输出,即以输入位的表达式来计算。e.g.

Approximating Sboxes
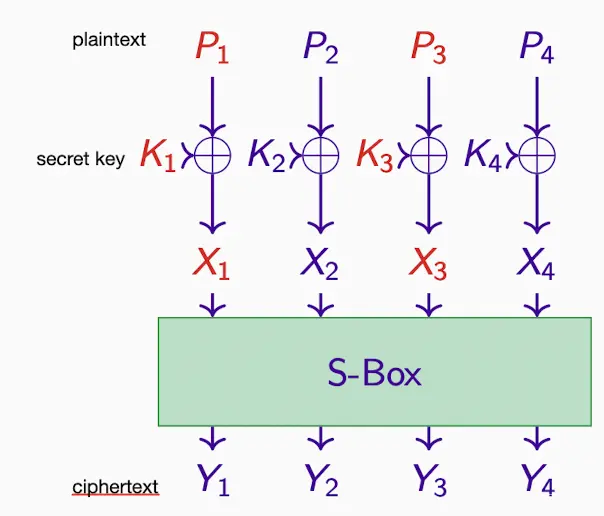
one key XORing and one Substitution Box
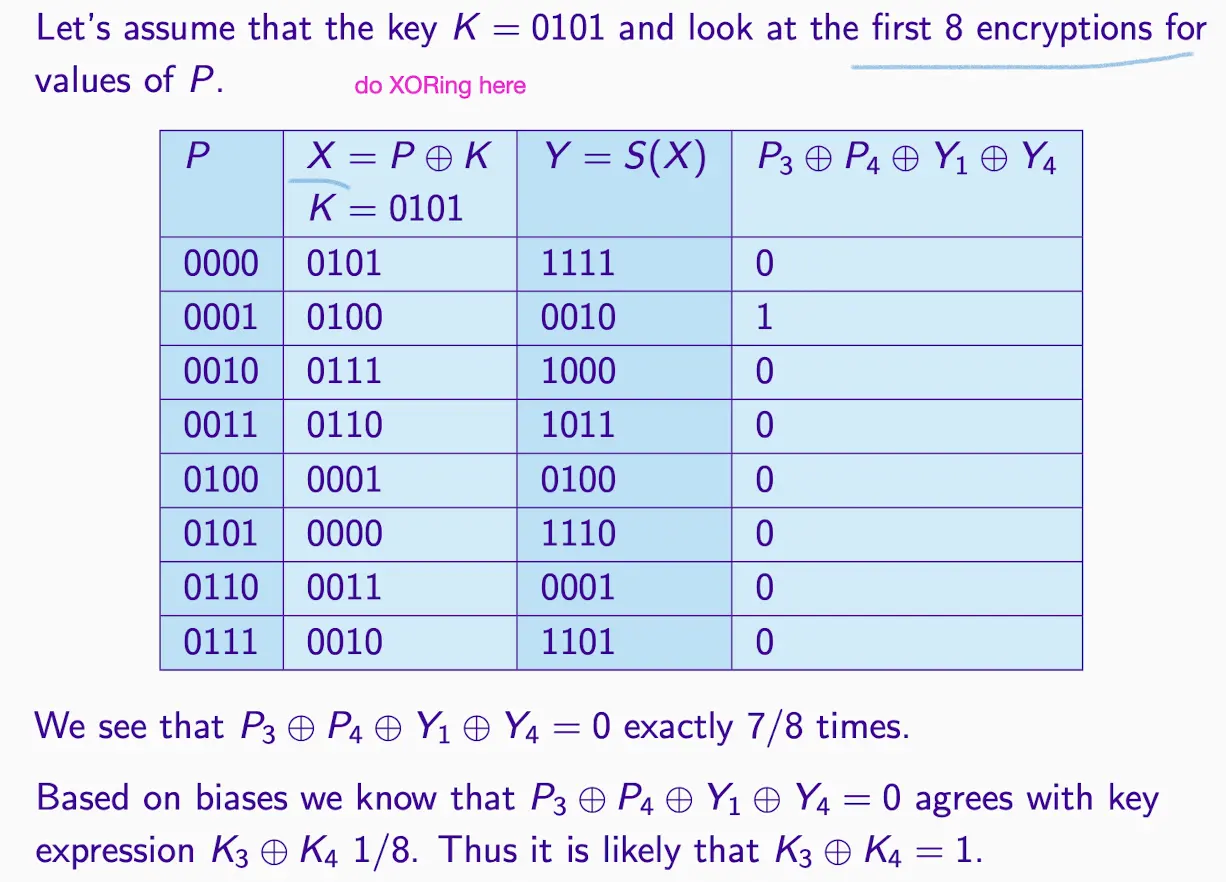
假设 X3 ⊕ X4 = Y1 ⊕ Y4,
那么 K3 ⊕ K4 = P3 ⊕ P4 ⊕ Y1 ⊕ Y4
Linear Approximation Table (LAT) for S-boxes
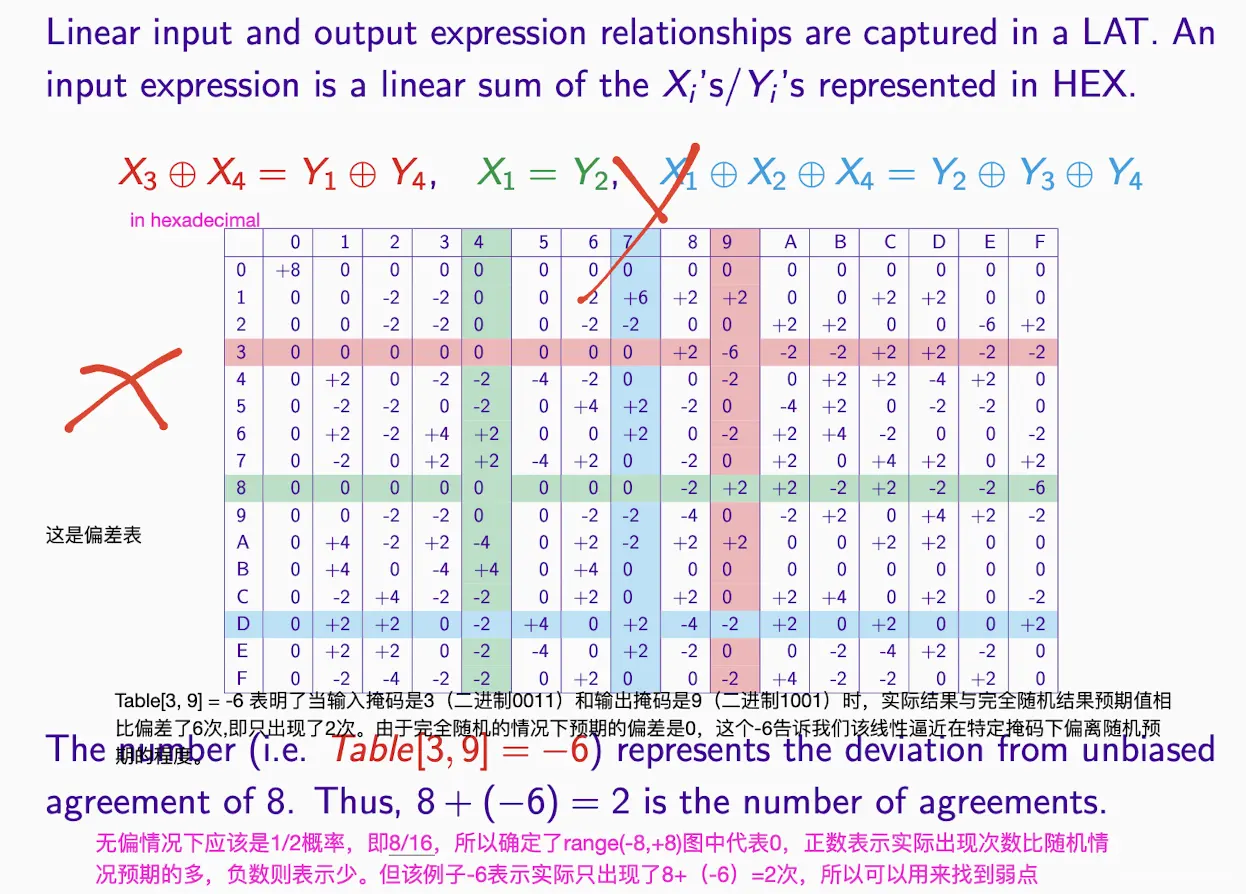
分析:
- x表示输入,y表示输出
- 这是偏差表:
- 0表示无偏,则probability为0.5。
- +表示实际出现比预期多了,-表示实际出现比预期少了
- 不为0则表示有信息,绝对值越大包含信息越多
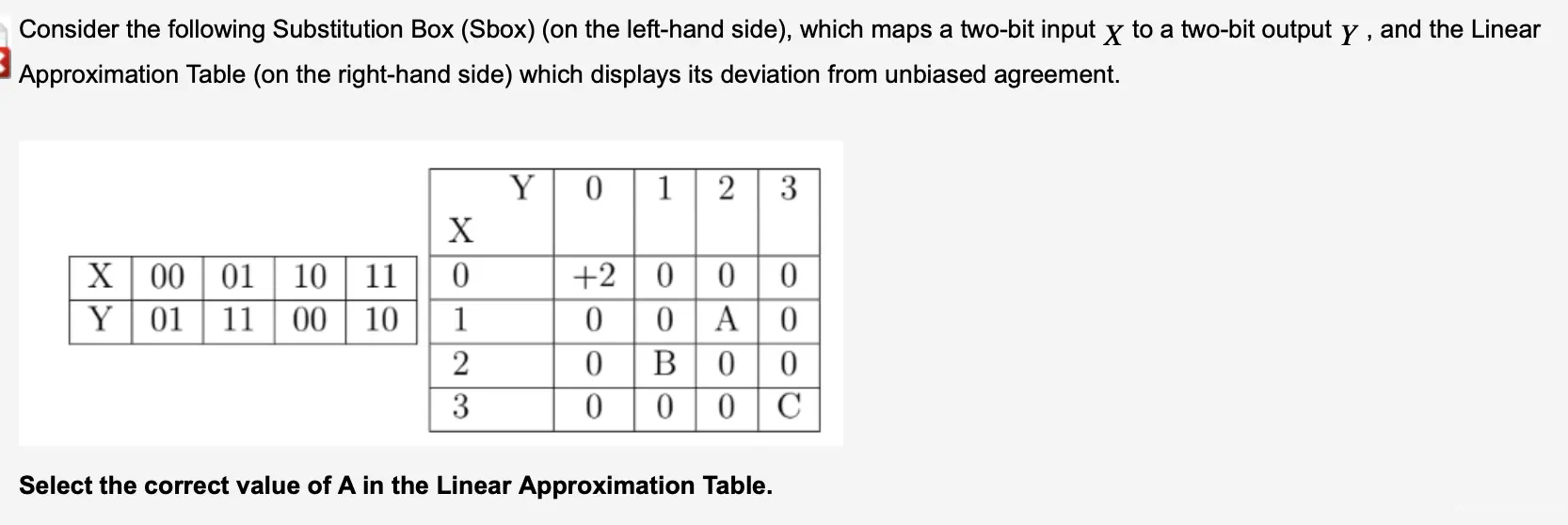
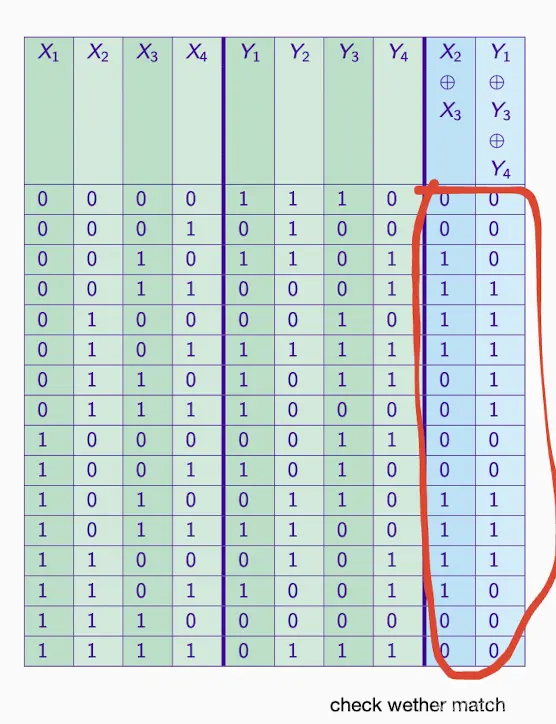
A[1,2] 意味着输入掩码为 ‘01’,这意味着我们只关心输入的第二位。输出掩码为 ‘10’,这意味着我们只关心输出的第一位。
计算每个输入对应的输出位的XOR值
我们需要对每个输入执行以下子步骤:
- 查看S-box中该输入的输出值。
- 将输入掩码应用于输入值,只保留掩码对应位为1的位。
- 将输出掩码应用于输出值,同样只保留掩码对应位为1的位。
- 计算这两个位的XOR值。
01 00 11 10 → 1010
11 01 10 00 → 1010
XOR → 0000 = 4/4
so answer is +2
also for B answer is -2
Matsui’s Piling Up Lemma
用来计算多个变量的偏差
- e.g. :bias 不为0

- e.g.: 只要有一个为0,最终结果就是无偏。例子Z2 是无偏的,有效地随机化了Z1 ⊕ Z2

- 结论:公式如下

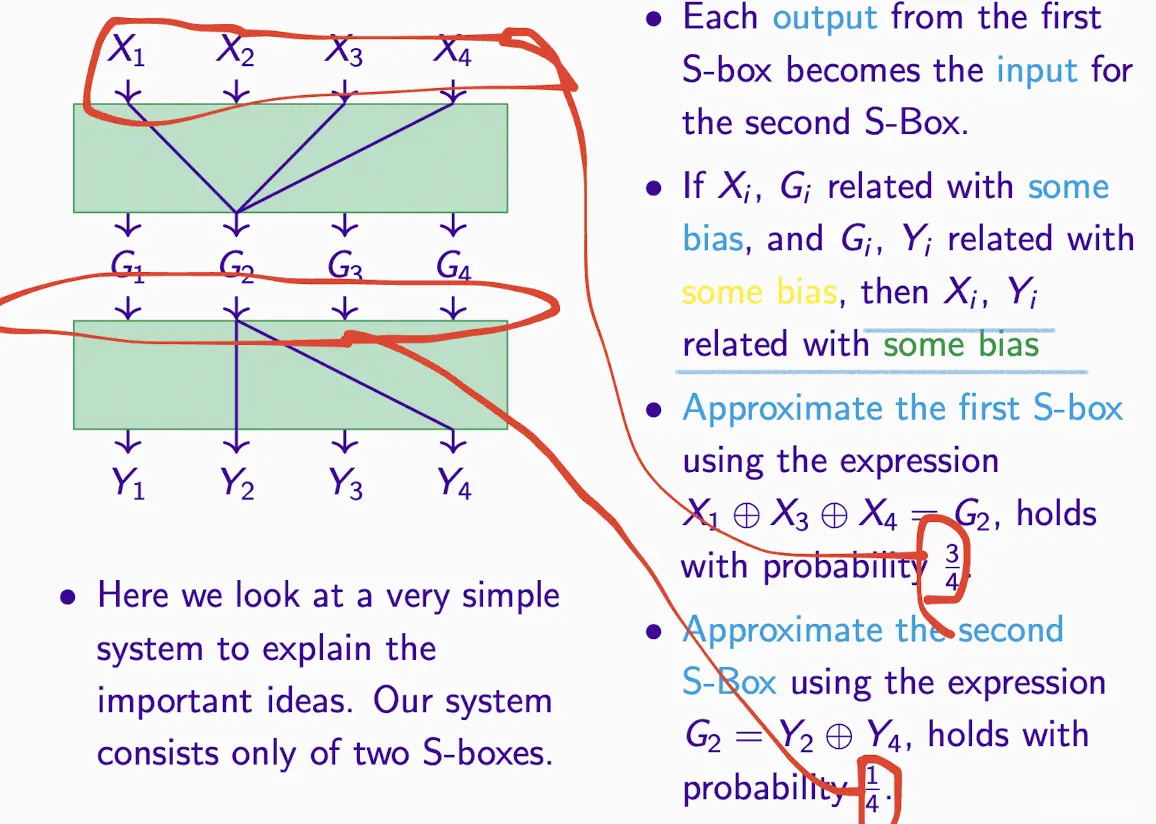
Linking S-box Approximations
步骤:
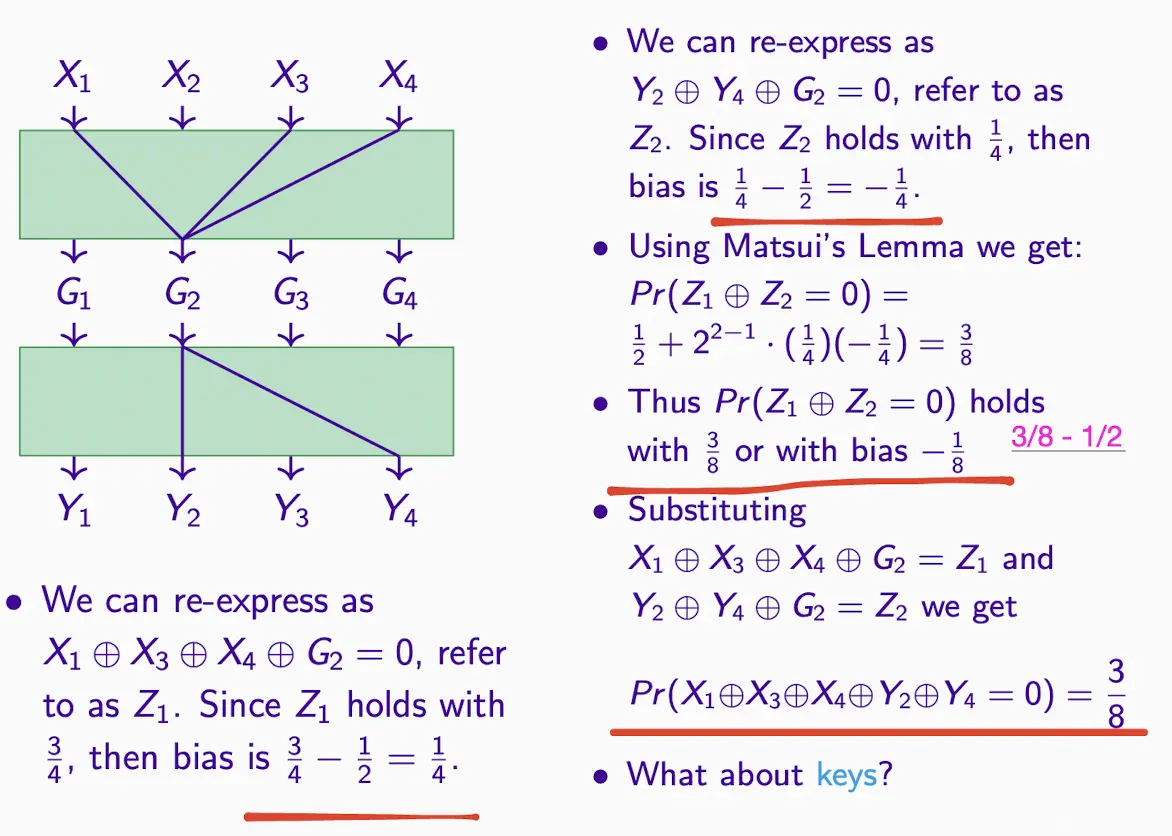
- 如何计算probability?根据input而不是output,如图例子得出G2的近似值
- 有了近似值,减去预期概率(一般是1/2)得到bias
- 共同XOR,消掉中间节点变到等号右边,变成求=0的概率
- 带入Matsui’s Lemma公式求该值
- 继续算整体的,例子如下
- Substituting步骤中都出现了G2,所以XOR变成0,变到等号右边
- 同时求出=1的概率为5/8
- 转换例子
- 计算例子
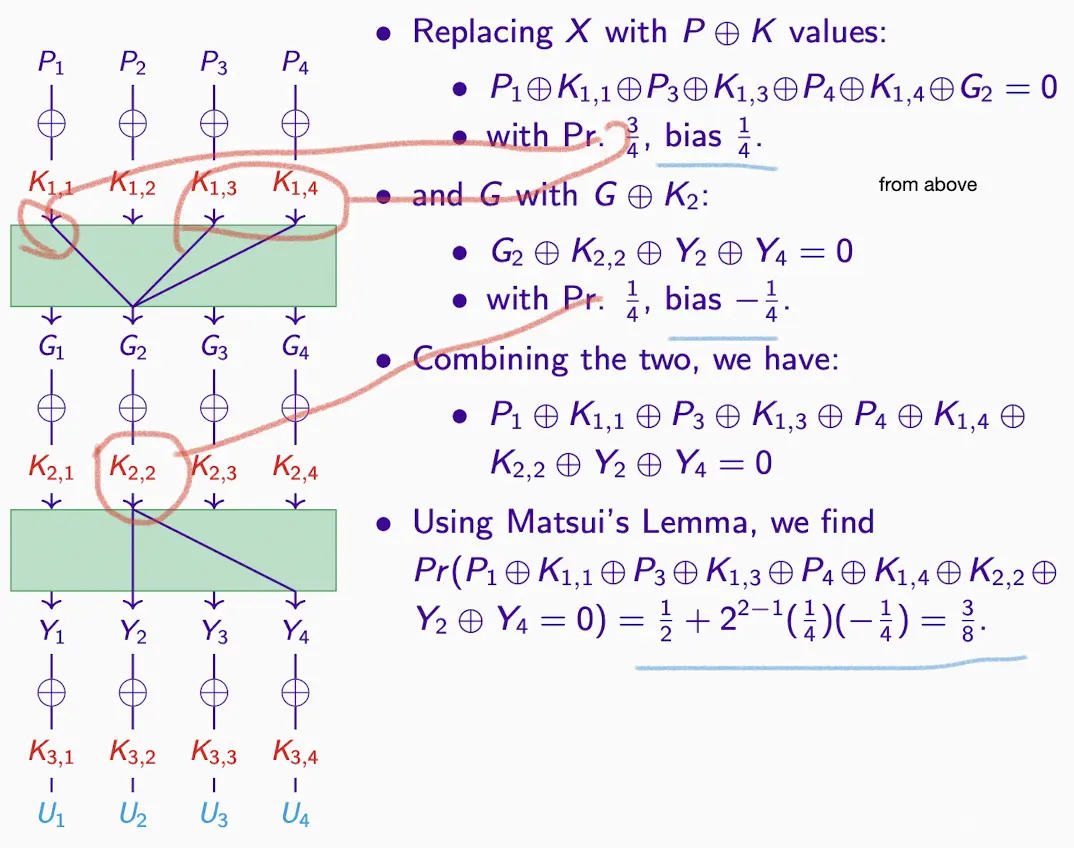
- 上例XOR公式的转换,所以结果一样

- 以上转换的总结
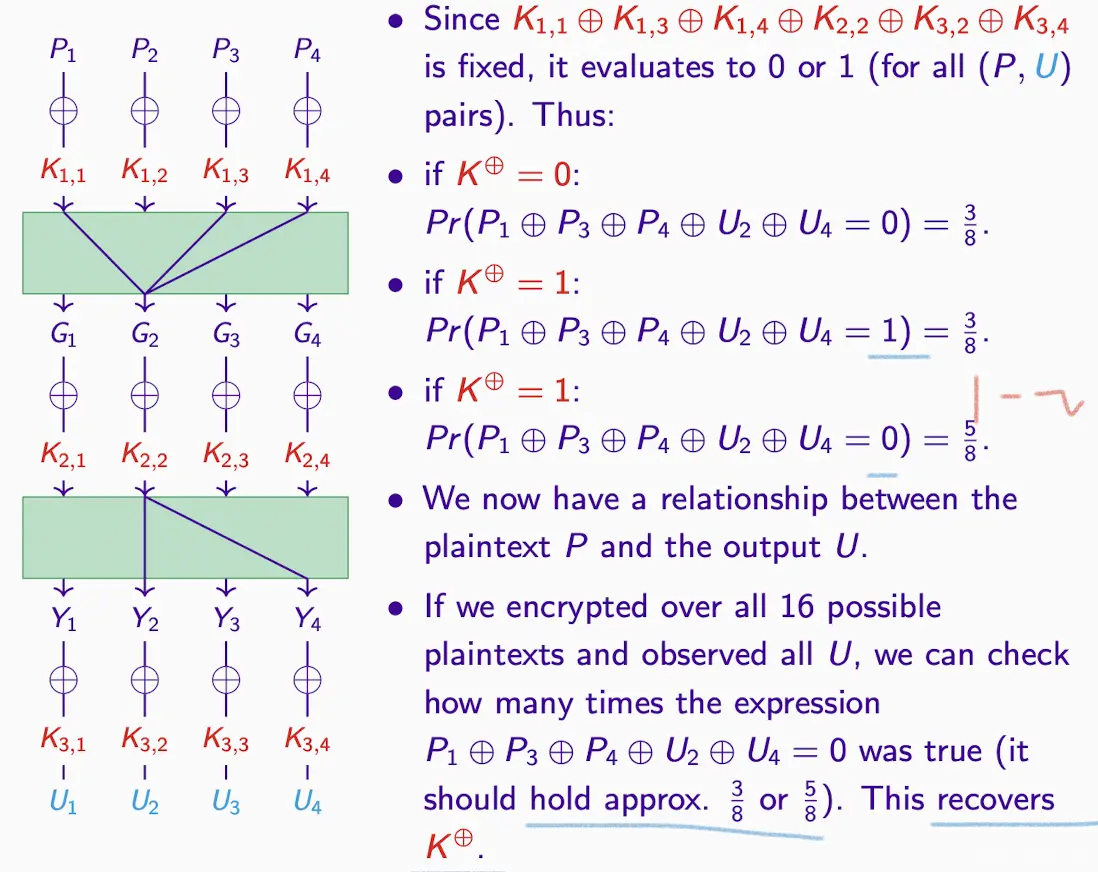
Discovering Keys
可见?
- 该系统只有plaintext P 和 ciphertext C 可见,毕竟是线性密码分析
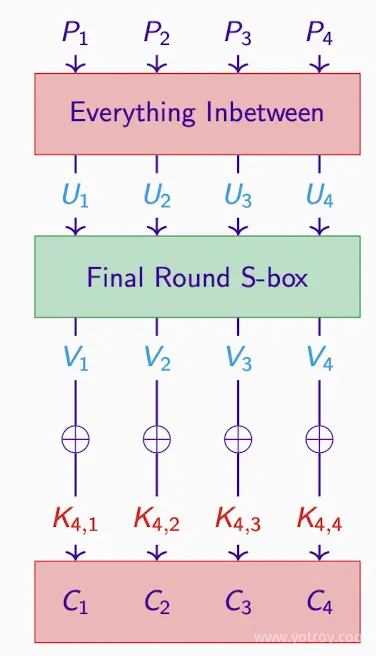
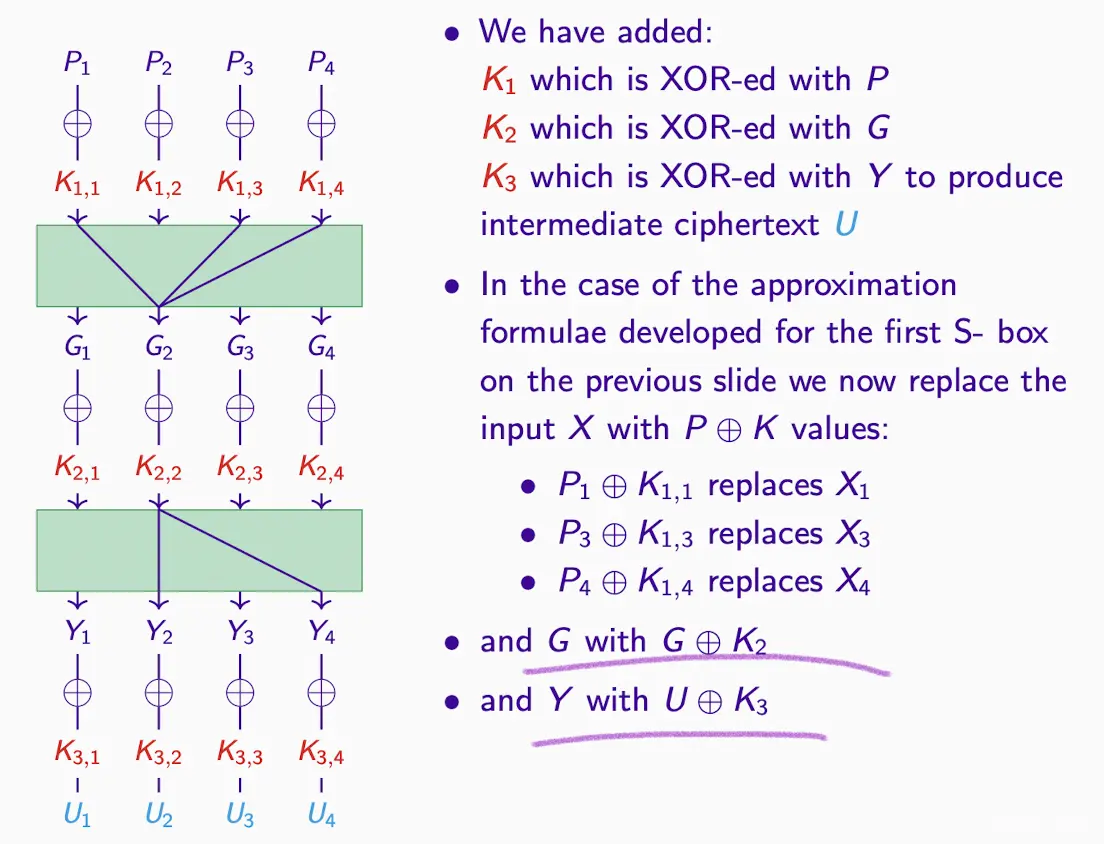
Final Round Key
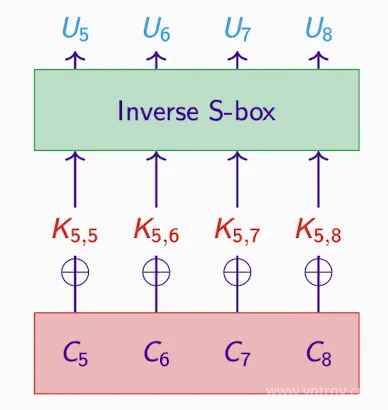
最后一轮S-box是可逆的invertible,所以可以算出对应的 U
对于密码分析者猜测的任何一轮密钥,他们都能生成 U
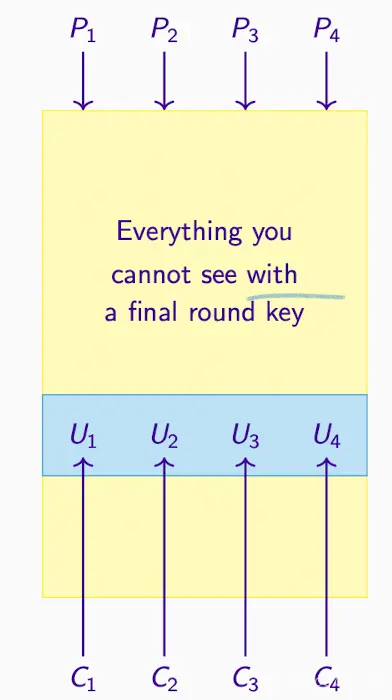
- 假设一个最后一轮密钥,得到中间密文,这代表了加密过程中的U1, U2, U3, U4等中间步骤。
- 如果猜测的密钥是正确的,那么中间密文就是正确的。
- 接下来,有了P和U和C计算近似表达式(approx. expression),它有一定的偏差(bias),比如1/8或者3/8。
- 如果这个近似表达式与观察到的偏差匹配,那么可以认为假设的密钥是正确的。
- 如果猜测的密钥是错误的,则中间密文也是错误的。
- 如果一个或多个密钥位猜错了,那么这个近似表达式将只会有1/2的时间成立,因为结果是随机化的。
因此,通过比较假设密钥下的近似表达式与1/2的偏差,可以区分出正确或错误的密钥猜测。最后,尝试所有可能的最后一轮密钥,看看哪一个的(P,U)近似值与1/2的偏差最不一致,这个密钥很可能就是实际的密钥。
Applying
Substitution Permutation Network( Hey’s Cipher)
- 在这个体系中,Heys’ Cipher通过重复的替代和置换操作以及密钥混合来增强加密的安全性。
- 3轮S-box: XORing,所有的S-box都是相同的。
- P-box: 置换盒,permuting,它按照特定的规则重新排列位,以扩散每轮中输入的任何变化。
- 16位子密钥: 假设为独立生成,通常是通过密钥计划得到,类似于DES(数据加密标准)中的做法。
- 例子:每个probability都是input
- 密钥混合采用的是逐位异或操作。
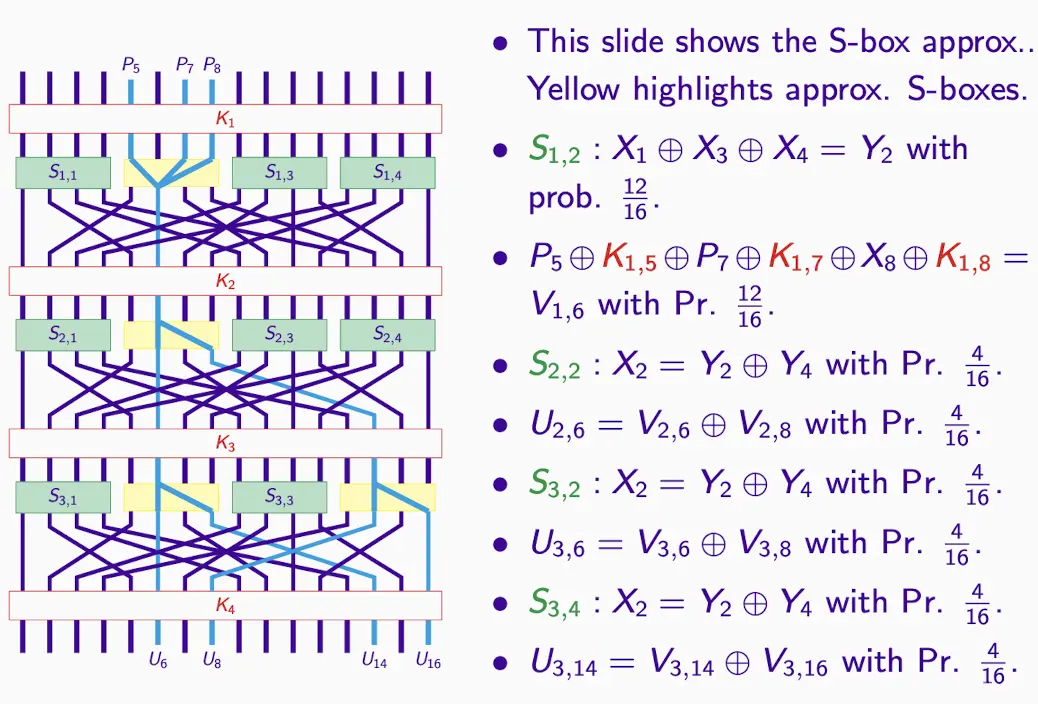
-
E2E指的是端到端的近似,从明文到密文的整个加密流程。


如果你拥有足够多的明文-密文对,理论上你可以利用这种线性近似来解密或更准确地猜测密钥。
-
如何计算? 同样Matsui’s Lemma
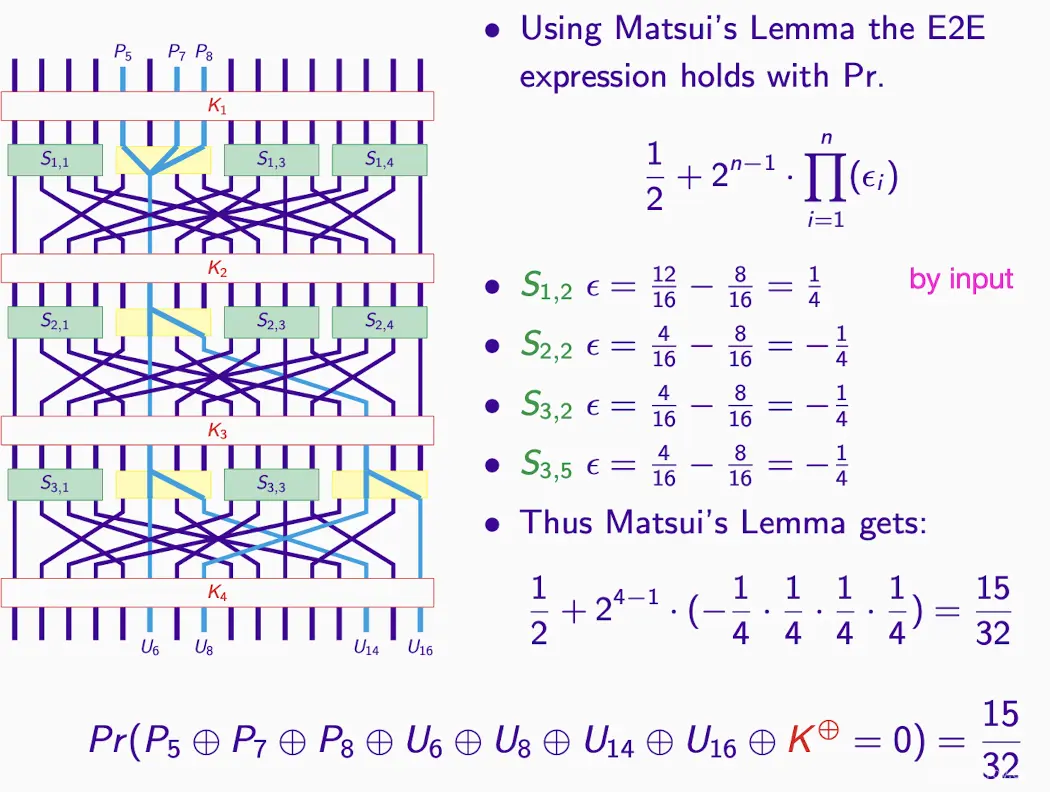

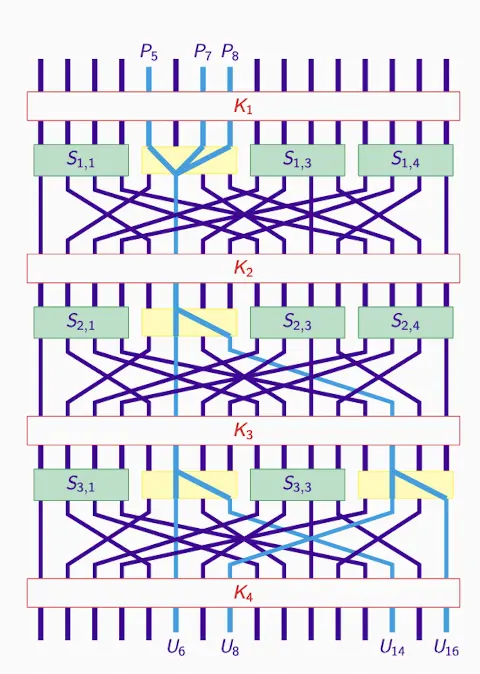
关键子块和反推:
- 目标:生成Intermediate Ciphertexts,通过K5和C(第二和四个subset)
- 和1st和3rd subset无关,所以interest是2nd和4th。
C到U,正确K得到正确U,反之亦然
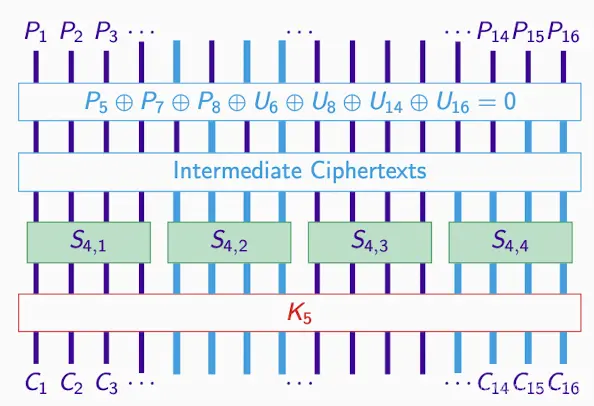
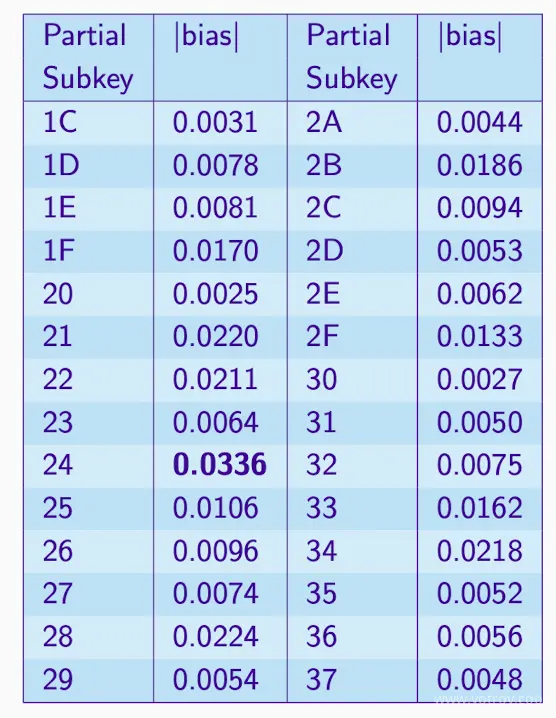
Try All Subkeys
- 表中只展示了一部分子建,假设有64个subkeys
- 假设有10000个ptxt-ctxt对,使用64个subkeys
- 对于每个p-c对,c和subkey生成p,计算bias
- 偏差最大的子键通常是正确的,但并不总是。
- 可以看到subkeys为24时bias最大,候选